Některé systémy již nativně prezentují data metrik v takovém formátu, kterému Prometheus rozumí (např. Ceph, Envoy, Docker Daemon, Etcd, GitLab, Kong, Minio, RabbitMQ a mnoho dalších). Nativně to může dělat i Vaše aplikace. Většina programovacích jazyků dnes již disponuje knihovnami, které generování metrik maximálně zjednodušují (Go, Java, Scala, Python, Ruby, PHP, R, …).
Prometheus si ale poradí i s takovými systémy, které metriky v jeho formátu publikovat neumí. Pro tyto účely je určen tzv. exporter. Ten na jedné straně sbírá data metrik z nativního API dané technologie a pomocí HTTP serveru je prezentuje ve formátu vyžadovaném Prometheem. Takových exporterů existuje nepřeberné množství. Ať už si vyberete téměř jakoukoliv dnes běžně využívanou technologii, je pravděpodobné, že pro ni již někdo takový exporter vytvořil. Týká se to síťových technologií, databází, hardware, aplikací, cloudů a jejich vlastních systémů pro sběr metrik a mnoha dalších.
Scénářů, jak provozovat exportery je mnoho. Může být nasazen jako side-car kontejner samotné aplikace nebo třeba další proces ve VM aplikace. Může ale běžet i uvnitř Kubernetes a vzdáleně sbírat data metrik z API nějaké komponenty mimo cluster.
Vizualizace metrik
Paralelní sběr metrik z kontejnerizovaných i tradičně operovaných aplikací, infrastrukturních komponent, middleware apod. přináší celou řadu možností. Vizualizace vztahů mezi nimi může odhalit celou řadu problémů, které nemusí být na první pohled zřejmé.
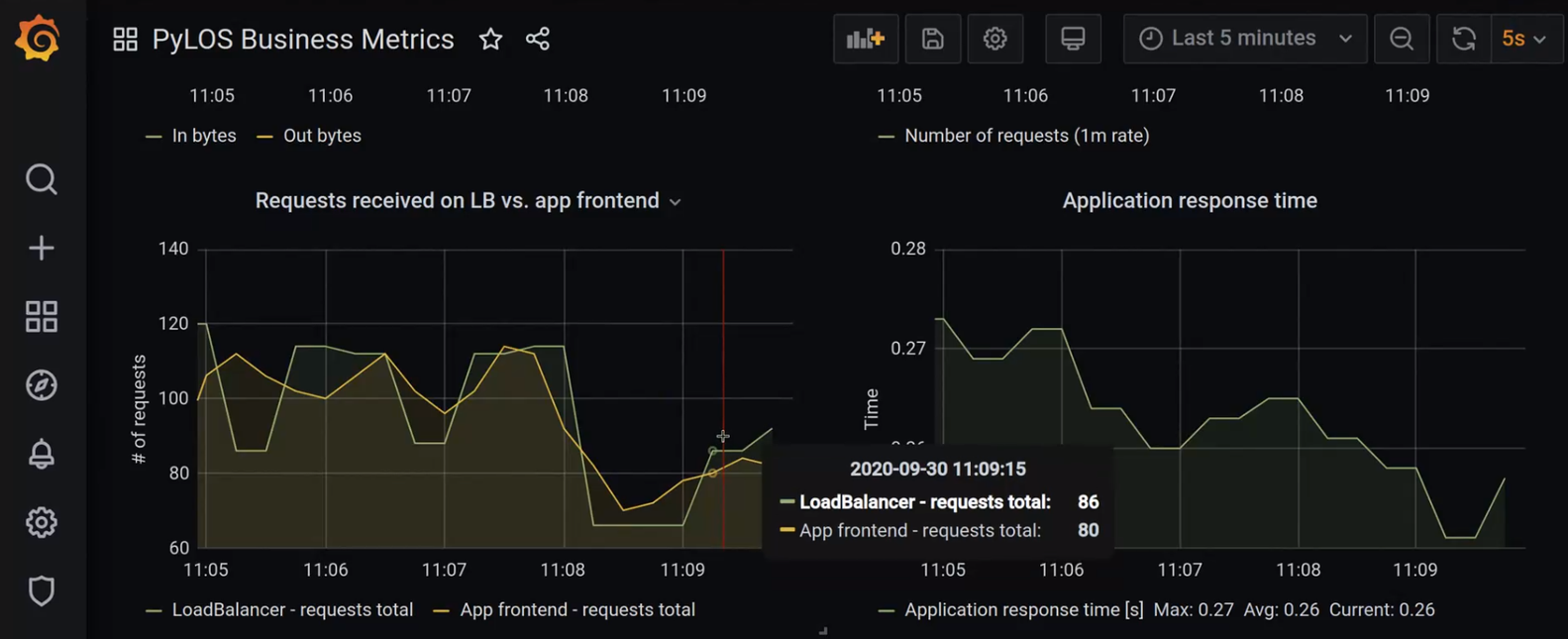
Na levém grafu následujícího obrázku je například vidět rate REST API požadavků přicházejících na HAProxy edge load-balancer a na aplikační frontend. Lišící se čísla obou křivek mohou indikovat problém na cestě mezi edge load-balancerem a aplikací.
Nezapomínejme, že zpracovávat můžeme nejen data technických metrik. Vaše aplikace mohou publikovat také data business metrik. Např. stav zboží na skladě, objem příchozích objednávek apod. I pro business metriky lze navíc definovat alerty a při jejich aktivaci na ně zase automatizovaně reagovat. Na Red Hat Forum 2020 jsme nedávno prezentovali ukázku, kdy se při nedostatku zboží na skladě aktivoval alert, který skrze Alert Managera spustil serverless funkci nasazenou v AWS Lambda. Jakkoliv tohle není typický scénář využití Prometheus stacku, zajímavě ilustruje možnosti, které s sebou takto konstruované řešení pro zpracování metrik přináší.
Prometheus je technologie vhodná pro tradiční i cloudovou infrastrukturu, která dokáže agregovat data metrik ve statickém i dynamicky škálovaném prostředí - díky svému velmi dobře vystavěnému konceptu discovery. Definici agregovaných metrik pak nechává na samotných sledovaných systémech. Pro zavádění nových targetů a metrik tím pádem není zapotřebí konfigurační zásah ze strany monitoring týmu a definice těchto metrik se místo toho stává součástí životního cyklu samotných sledovaných systémů.