
Vývoj AI aplikací se rychle posouvá z prototypů do reálného nasazení. Firmy hledají způsoby, jak bezpečně experimentovat s modely, integrovat je do svých DevOps procesů a zároveň udržet kontrolu nad daty i náklady. Právě zde vstupuje na scénu Podman AI Lab, novinka, která rozšiřuje funkce populárního container engine Podman o přehledné rozhraní pro práci s AI.
Podman AI Lab přináší možnost jednoduše vytvářet, spravovat a testovat AI řešení přímo lokálně – bez odesílání dat do cloudu a bez nutnosti složitých nástrojů. Pro DevOps týmy a architekty jde o výrazné zjednodušení celého procesu.
3 min read
Red Hat Podman AI Lab: Bezpečné a efektivní experimentování s AI v kontejnerech

Topics: Red Hat OpenShift AI DevOps OpenSource Automation Podman AI Lab
8 min read
SELinux: Noční můra adminů nebo šance na lepší spánek?

Nedávno jsem byl na schůzce s klientem, kde popisovali svou linuxovou infrastrukturu a mimo jiné zmínili, že na RHEL operačních systémech mají vypnutý SELinux. Protože téma diskuze bylo jiné, tak jsem nepoložil základní otázku: „Proč?”
Topics: Red Hat Enterprise Linux SELinux Security Training
6 min read
OpenShift Local jako nástroj pro nasazení HashiCorp Vault v praxi
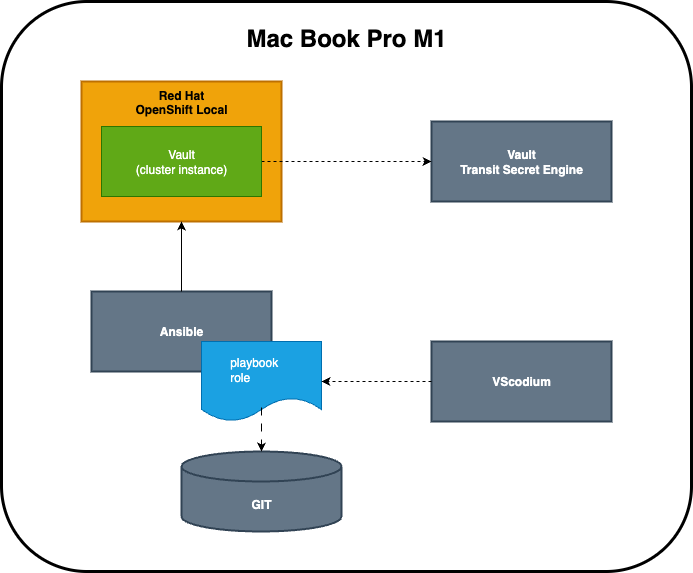
Pojďme se v článku seznámit s použitím Red Hat OpenShift Local na reálném use-case. Zároveň si odpovíme na otázku, zda jeho použití naplňuje prvky antického dramatu.
Topics: DevOps Kubernetes Ansible OpenShift Local Git Red Hat OpenShift
4 min read
Jujutsu: Moderní alternativa ke Gitu bez (tolika) bolesti

Git je už dávno standardem pro správu verzí. Ale přiznejme si – kdo z nás si v něm nikdy "neustřelil nohu"? Na první pohled nenápadný překlep, špatně provedený rebase nebo špatně pojmenovaný commit… a je zle. Právě na tyhle chvíle míří nový nástroj z dílny Googlu – Jujutsu (zkráceně jj), který chce verzování zjednodušit, zpřehlednit a zpříjemnit. A to bez přetrhání pout s Gitem.
Topics: DevOps OpenSource Jujutsu rust Git Alternativa
4 min read
Když potřebujete výkon a spolehlivost: Red Hat AI Inference Server v praxi

Umělá inteligence se stává součástí běžných IT operací. Firemní týmy už dávno neřeší jen to, jak model natrénovat, ale hlavně jak ho stabilně a bezpečně provozovat. A právě tady přichází na scénu Red Hat AI Inference Server – open source nástroj, který umožňuje nasazení AI modelů do produkce ve velkém měřítku, automatizovaně a v souladu s podnikovými standardy.
Topics: Red Hat OpenShift AI DevOps Kubernetes Automation AI Inference MLOps Edge Computing
2 min read
Red Hat Developer Hub: Váš vývojářský portál bez kompromisů

Red Hat Developer Hub (RHDH) je moderní portál pro vývojáře, který organizacím umožňuje mít přehled o vývoji, dokumentaci, API i procesech – vše na jednom místě. Je postaven na komunitním projektu Backstage, ale Red Hat jej vylepšuje o funkce, které jsou důležité pro enterprise prostředí: škálovatelnost, bezpečnost, podporu a snadnou integraci do existující infrastruktury.
Topics: DevOps Kubernetes RedHatDeveloperHub Automation BackstageIO
5 min read
Zlepšená správa mikroservisů: OpenShift Service Mesh 3.0 je tady!

S rozmachem mikroservisní architektury narůstá i potřeba nástrojů, které usnadní jejich správu, sledování a zabezpečení. Red Hat proto uvádí OpenShift Service Mesh 3.0, novou generaci řešení pro správu komunikace mezi službami v rámci OpenShift prostředí. Tato verze přináší výrazný posun směrem k modernímu, flexibilnímu a škálovatelnému přístupu ke správě servisní sítě.
Topics: OpenShift DevOps Red Hat Kubernetes Service Mesh Cloud Native Container Management Enterprise IT
2 min read
Je Docker opravdu open-source? Rizika pro vývojová prostředí a enterprise projekty

Docker je dnes jedním z nejpoužívanějších nástrojů pro kontejnerizaci aplikací. Mnoho firem a vývojářů na něm staví svou infrastrukturu, ať už v on-premise prostředí, nebo v cloudu. Často se ale setkáváme s tím, že vývojová prostředí běží "v šuplíku pod stolem" u jednotlivých vývojářů, což může představovat riziko z hlediska spravovatelnosti a dlouhodobé udržitelnosti. Proto se objevuje otázka, zda je Docker skutečně open-source a co to může znamenat pro firmy, které na něm závisí.
2 min read
Neviditelné náklady IT: Jak správně plánovat a řídit rozpočet

Počítali jste někdy odhad IT nákladů pro product pitch na řešení, se kterým v dané podobě nemá nikdo ve firmě přímou zkušenost? Zejména v ideační fázi, kdy je mnoho věcí nejasných, se hlavní úsilí soustředí na stanovení přibližné úrovně nákladů. Podle komunikační potřeby se do těchto čísel přidává i nějaké konkrétní, ideálně nezaokrouhlené číslo, aby výsledek působil důvěryhodněji a vědečtěji pro sponzora. Takto vzniklé číslo se pak použije pro rozhodovací proces nebo stanovení finančního rámce. Abychom se vyhnuli faux pas, nebudeme se zde zabývat opačnou stranou rovnice, tedy formulací očekávaných výnosů.
Během samotného vývoje, ať už v rámci designu nebo při práci vývojářů, často dochází k významným změnám. Objevují se dodatečné integrace, které původně nebyly plánovány, ale stávají se nezbytnými po zpřesnění zadání. V moderních metodikách vývoje analýza i design pokračují souběžně s vývojem, což vede k činorodé výměně názorů a kompromisů. Pokud návrh kompromisu není schválen, následují naléhavé schůzky s product ownery dotčených aplikací. Jejich výsledkem často bývá postoj "ono se to tam vejde", což v danou chvíli situaci formálně řeší, ale reálně se na náklady zapomíná. Zvýšené náklady se přelijí do jiného budgetu, a pokud má někdo rezervy nebo počítá s růstem v rámci business as usual, věří se, že se někde ztratí. Nejčastější obětí jsou oddělení, která nejsou přímo spjata s business funkcionalitou, a jsou tedy v náhledu firmy pouhým nákladem.
Pokud vše dopadne dobře, aplikace je nasazena do pilotního provozu a následně do produkce. DevOps tým či product owner dostane jednou za kvartál nebo i ročně výstup z interního rozúčtování on-premises komponent. Pokud se používá cloud, je denně k dispozici detailní billing. Ovšem s odstupem času se již většinou nikdo nezabývá skutečnými náklady na celkovou business službu nebo produkt. Většinou se sledují pouze náklady konkrétní aplikační infrastruktury, která se dá prezentovat zjednodušeným modelem. Sledovat reálné náklady je složité, sdílené služby nejsou dostatečně rozlišené a často zatěžují týmy, které není business schopen identifikovat jako užitečné.
Business tak často zjistí, že si objednal něco jiného, než dostal, a zaplatil za něco, co původně nechtěl. Ale vlastně ne tak docela – protože většinou nemá přesné informace o tom, co jeho požadavek skutečně stál. Modely nákladů se různě liší a jejich přesnost závisí na důslednosti DevOps týmů a schopnosti sdílených služeb efektivně komunikovat. A jak asi tušíte, většinou komunikovat neumějí. To vede k dojmu, že IT provoz je čím dál dražší a netransparentní. V reakci na to se business snaží implementovat SaaS řešení, která IT obcházejí – ale paradoxně se IT nakonec vrátí přes identitní služby, integrace a data.
Část nedůvěry v IT pramení z toho, že nepracuje na servisně orientovaném přístupu. Každá business služba by měla mít transparentně stanovenou cenu a billing, ale tradiční přístup IT soustředěný na celkové náklady už nestačí. Moderní enterprise architektura rozděluje business funkce a data, což přináší větší přehlednost a flexibilitu, ale komplikuje billing. Skutečně užitečné FinOps metriky si proto musí každá organizace definovat sama.
Aby IT zůstalo partnerem businessu, musí transparentně komunikovat náklady a spoluvytvářet varianty rozvoje. Vestavěné sledování billable metrik pomůže propojit náklady s produkty a službami, i když to vyžaduje změnu firemní kultury. Pak možná bude "zpětné vyhodnocení business case" vyvolávat méně nervózního smíchu. Držme si palce.
Topics: ITnáklady FiremníFinance finops Business Case ITbudgeting CloudComputing ITstrategie NákladováOptimalizace Digitalizace EnterpriseArchitecture DevOps ITvsBusiness Billing SaaS
3 min read
Red Hat OpenShift AI
Red Hat® OpenShift® AI je flexibilní, škálovatelná platforma pro umělou inteligenci (AI) a strojové učení (ML), která umožňuje podnikům vytvářet a dodávat aplikace s podporou AI ve velkém měřítku napříč hybridními cloudovými prostředími. OpenShift AI, postavený na open source technologiích, poskytuje důvěryhodné, provozně konzistentní schopnosti pro týmy, které experimentují, nasazují modely a dodávají inovativní aplikace.
Topics: AI Budoucnost AI Platforma pro AI řešení
Chcete se dozvědět více?
Prostě jen klikněte na tlačítko níže a zarezervujte si s námi bezplatnou konzultaci.
