
V rámci diskusí na téma distribuovaných aplikací téměř vždy zaznívá téma observability. Formálně lze observability definovat jako míru pozorovatelnosti a porozumění vnitřním událostem a procesům daného systému. Mikroservisní architektura dnešních distribuovaných aplikací observabilitu jako téma nijak nezjednodušuje, spíše naopak. Obvykle se v takové architektuře využívá enormní množství technologií a rychlost jejich změn je dechberoucí.
Abychom měli dostatek informací potřebných k pozorování systému, potřebujeme sbírat, interpretovat a vzájemně korelovat data z různých zdrojů. Tradičními pilíři v oblasti pozorovatelnosti systémů jsou
- Tracing - trace je reprezentace řady kauzálně souvisejících událostí, generovaných postupem jednoho kompletního požadavku skrze distribuovaný systém,
- Agregace logů - je sběrem informací, generovaných ve formě časově identifikovatelního záznamu jedné události přímo aplikacemi nebo infrastrukturními komponentami,
- Metriky - prezentují informace o chování sledovaných systémů, nasbíraných v konkrétním časovém intervalu. Tato data lze pak dále zpracovávat matematickými modely.
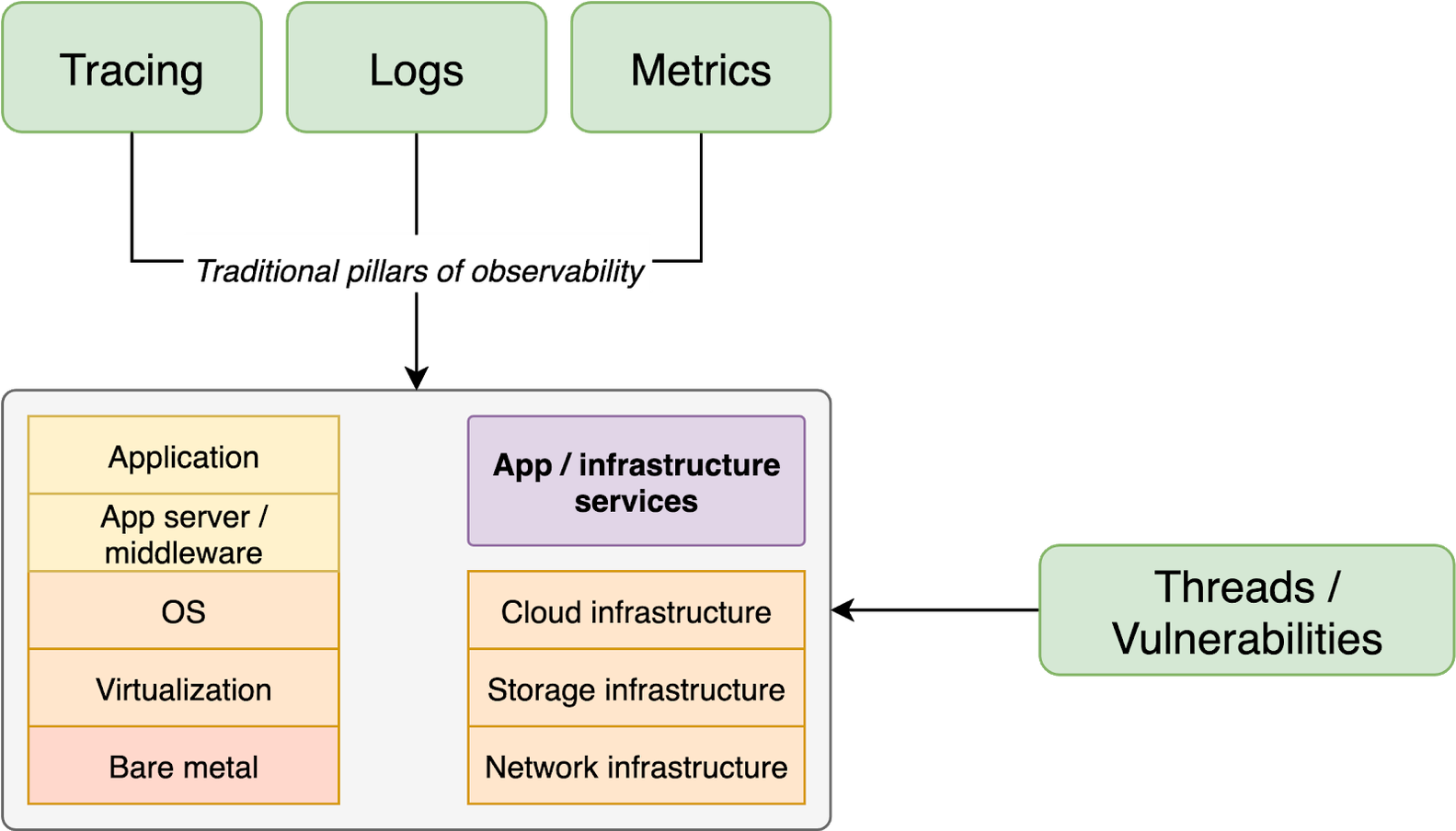
Pro znalost stavu systému je výhodné znát i rizika spojená s jeho provozem a vědět, jaké jsou zranitelnosti systému a hrozby s ním spojené. Případným výpadkům jsme tak schopni zabránit dříve, než se zranitelnost projeví. Zákazníci Red Hatu vědí (a nebo by rozhodně měli vědět), že pro některé jimi provozované technologie (RHEL, OpenShift, …) mají k dispozici technologii Red Hat Insights. Ta pomáhá predikovat rizika spojená s provozem systémů v oblastech výkonu, dostupnosti, stability i zabezpečení.
V tomto článku se zaměřím na oblast zpracování metrik.
Prometheus a jeho banda
Pro sběr metrik a monitoring systémů využíváme v enterprise prostředí celou řadu komponent.
První linie podpory typicky využívá nějaké monitorovací řešení, pomocí kterého identifikuje vznikající problémy a na jehož základě notifikuje druhou linii technické podpory (je to ta banda, která vám je ochotna volat kdykoliv mezi první a pátou hodinou v noci). Často je tímto systémem například Zabbix.

Další komponentou je Prometheus, kterého znají pravděpodobně všichni, kdo mají co do činění s kontejnerizační platformou Kubernetes. Ten má za úkol identifikovat sledované systémy a sbírat z nich data metrik, které ukládá do své time-series databáze. Má také za úkol vyhodnocovat stav uživatelem definovaných alertů a disponuje API rozhraním pro dotazování nad metrikami.
Prometheus je jedinečný tím, že je připraven pro dynamická prostředí. Dokáže realizovat discovery sledovaných systémů z velkého množství různorodých zdrojů (veřejné cloudy, virtualizační platformy, Red Hat Ansible Tower atd.). Sledovaný systém navíc sám definuje, jaké metriky bude Prometheus sbírat a pomocí jakého URL. Prometheus totiž sbírá všechny metriky, které sledovaný systém vystaví na daném URL. Definice metrik je tedy součástí aplikačního deploymentu - pro zavedení nových targetů a metrik není zapotřebí interakce mezi aplikačním vývojářem a týmem, který Promethea spravuje.
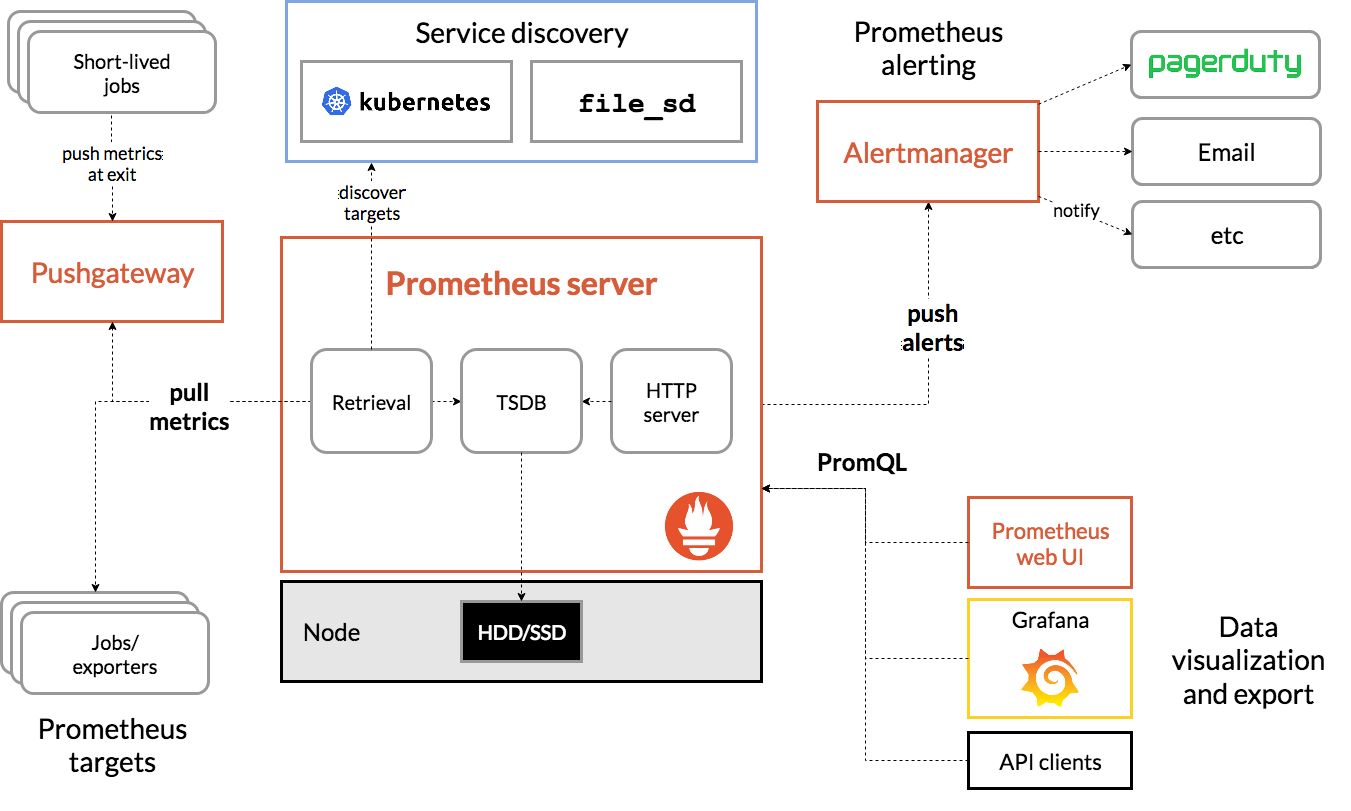
Systém Prometheus implementuje tzv. pull přístup: sám si periodicky stahuje data metrik ze sledovaných systémů (tzv. scraping). Každý target má za úkol pouze pasivně vystavit hodnoty metrik v definovaném formátu pomocí HTTP protokolu.
Součástí Promethea je i Alert Manager, který má za úkol rozesílat informace o tzv. firing alertech zainteresovaným uživatelům skrze aplikace jako jsou Jira, Slack, email apod. Informace o alertech umí předávat také dalším monitorovacím nástrojům (např. právě Zabbixu), ačkoliv právě tato integrace není vždy jednoduchá ani přímočará.
Pro uživatele, kteří potřebují detailní informace o chování systémů, je k dispozici Grafana, open source nástroj pro vizualizaci sbíraných metrik. Ta Prometheus podporuje nativně jako zdroj dat.
Sběr a korelace metrik z více zdrojů
V typickém zákaznickém prostředí řešíme často podobný problém: potřebujeme sbírat metriky aplikací běžících v mnoha Kubernetes clusterech v různých prostředích a ty zase potřebujeme korelovat s metrikami různých infrastrukturních komponent, jakými jsou typicky storage nebo load-balancery.
Podívejme se nejprve, jak řešíme problematiku sběru metrik na straně Kubernetes, v tomto případě OpenShiftu.
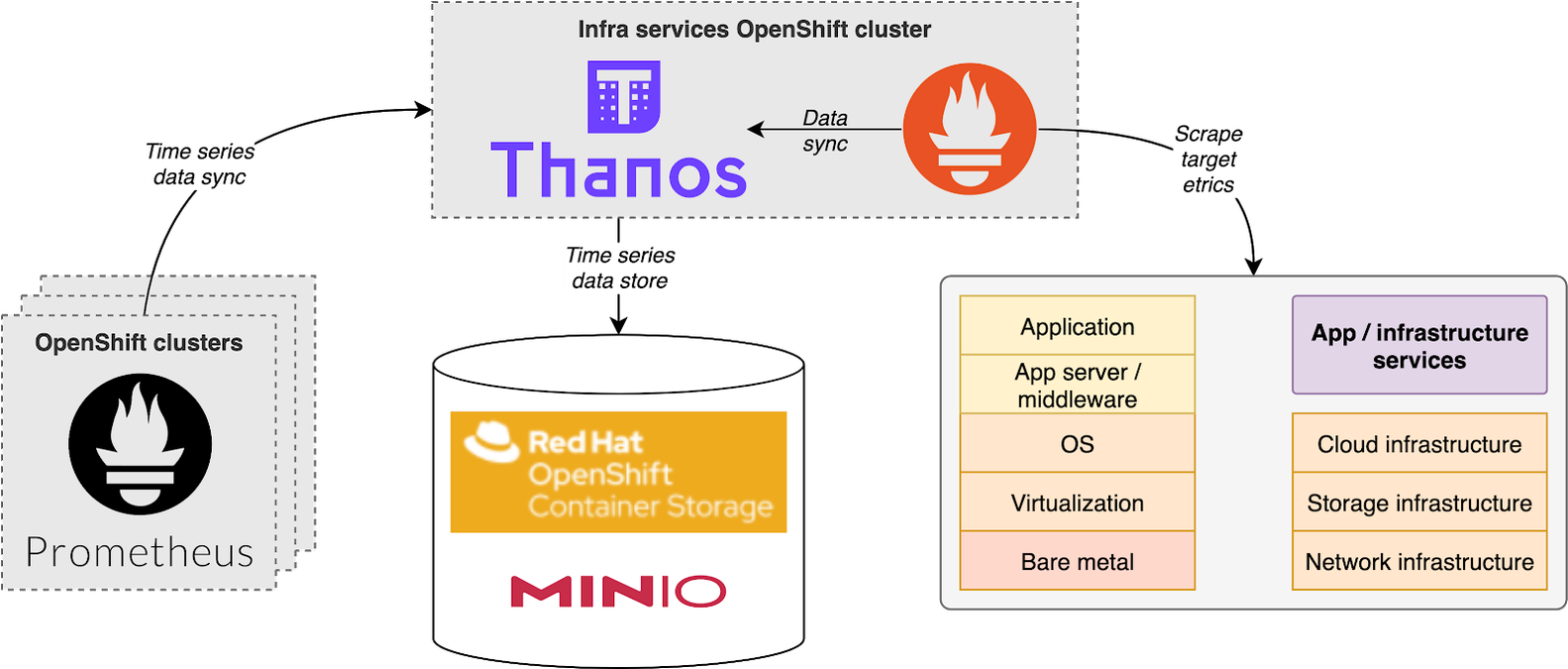
Sběr metrik v OpenShiftu
OpenShift je v tomto směru velmi dobře vybavenou platformou. V každém clusteru je k dispozici Prometheus stack ve dvou provedeních. První z nich má za úkol sbírat metriky komponent samotného clusteru. V tomto ohledu nás zajímají data týkající se utilizace nodů platformy, metriky API serverů apod. Součástí tohoto Promethea je také sada alertů dodávaných Red Hatem společně s OpenShiftem. Konfigurace tohoto stacku je řízena monitoring operátorem a je z větší části neměnná.
Druhý Prometheus má za úkol sbírat metriky aplikací, které jsou vystaveny aplikacemi provozovanými v OpenShiftu. Za tímto účelem může aplikační administrátor zodpovědný za deployment aplikace definovat tzv. ServiceMonitor custom resource, který Prometheovi pomocí Kubernetes labelů sděluje, z jakých služeb běžících v clusteru sbírat data metrik a pomocí jakého URL.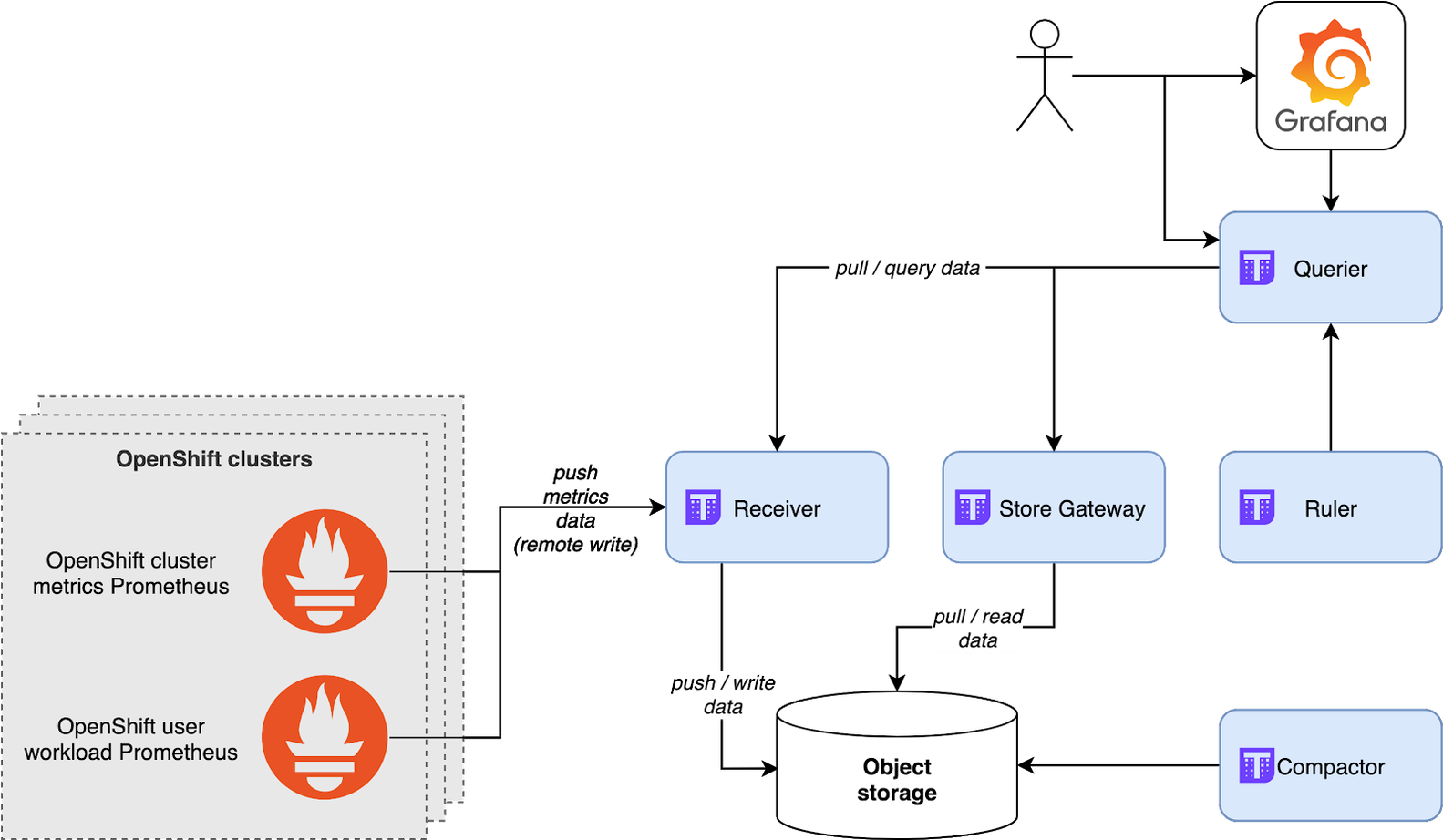
Každý instalovaný OpenShift také disponuje instancí Grafany, pomocí které lze vizualizovat metriky daného clusteru. Problém nicméně nastává v situaci, kdy zákazník provozuje několik OpenShift clusterů. V mnoha případech jich je 5 až 10, někdy i více. Jak tedy implementovat jedno uživatelské rozhraní pro vizualizaci metrik pro všechny OpenShift clustery? K řešení tohoto problému využíváme open source technologii Thanos. Nebudu zde rozebírat všechny její komponenty, nicméně úlohou Thanosu je agregovat data všech instancí Promethea ve své objektové storage (např. MinIO, AWS S3, Red Hat Container Storage apod.). Thanos publikuje stejné API jako Prometheus a je možné jeho směrem vysílat PromQL dotazy stejně jako proti standardní instalaci Promethea. Grafana tedy dokáže vizualizovat metriky sbírané ze všech clusterů. Data jsou také Thanosem otagována, aby bylo možné odlišit stejné metriky pocházející ze dvou různých clusterů. Chtěli jste někdy porovnávat např. vytíženost aplikace nasazené v active-active modu na dvou různých clusterech v jednom grafu? Zde je řešení!
Sběr infrastrukturních metrik
Podívejme se nyní na způsob, jak lze řešit sběr logů na infrastrukturní úrovni. Prvním tématem, které je zapotřebí řešit, je discovery targetů. Jak se Prometheus dozví, na jakém URL má metriky sbírat? Způsobů existuje mnoho. Prometheus si je dokáže vyčíst např. z Red Hat Ansible Toweru, z API veřejných cloudů, z API privátních virtualizačních a cloudových platforem (např. Red Hat Virtualization nebo OpenStack Platform). Jakmile má Prometheus seznam targetů pohromadě, začíná z nich s definovanou periodou sbírat data všech metrik, která o sobě daný systém zveřejní.
Některé systémy již nativně prezentují data metrik v takovém formátu, kterému Prometheus rozumí (např. Ceph, Envoy, Docker Daemon, Etcd, GitLab, Kong, Minio, RabbitMQ a mnoho dalších). Nativně to může dělat i Vaše aplikace. Většina programovacích jazyků dnes již disponuje knihovnami, které generování metrik maximálně zjednodušují (Go, Java, Scala, Python, Ruby, PHP, R, …).
Prometheus si ale poradí i s takovými systémy, které metriky v jeho formátu publikovat neumí. Pro tyto účely je určen tzv. exporter. Ten na jedné straně sbírá data metrik z nativního API dané technologie a pomocí HTTP serveru je prezentuje ve formátu vyžadovaném Prometheem. Takových exporterů existuje nepřeberné množství. Ať už si vyberete téměř jakoukoliv dnes běžně využívanou technologii, je pravděpodobné, že pro ni již někdo takový exporter vytvořil. Týká se to síťových technologií, databází, hardware, aplikací, cloudů a jejich vlastních systémů pro sběr metrik a mnoha dalších.
Scénářů, jak provozovat exportery je mnoho. Může být nasazen jako side-car kontejner samotné aplikace nebo třeba další proces ve VM aplikace. Může ale běžet i uvnitř Kubernetes a vzdáleně sbírat data metrik z API nějaké komponenty mimo cluster.
Vizualizace metrik
Paralelní sběr metrik z kontejnerizovaných i tradičně operovaných aplikací, infrastrukturních komponent, middleware apod. přináší celou řadu možností. Vizualizace vztahů mezi nimi může odhalit celou řadu problémů, které nemusí být na první pohled zřejmé.
Na levém grafu následujícího obrázku je například vidět rate REST API požadavků přicházejících na HAProxy edge load-balancer a na aplikační frontend. Lišící se čísla obou křivek mohou indikovat problém na cestě mezi edge load-balancerem a aplikací.
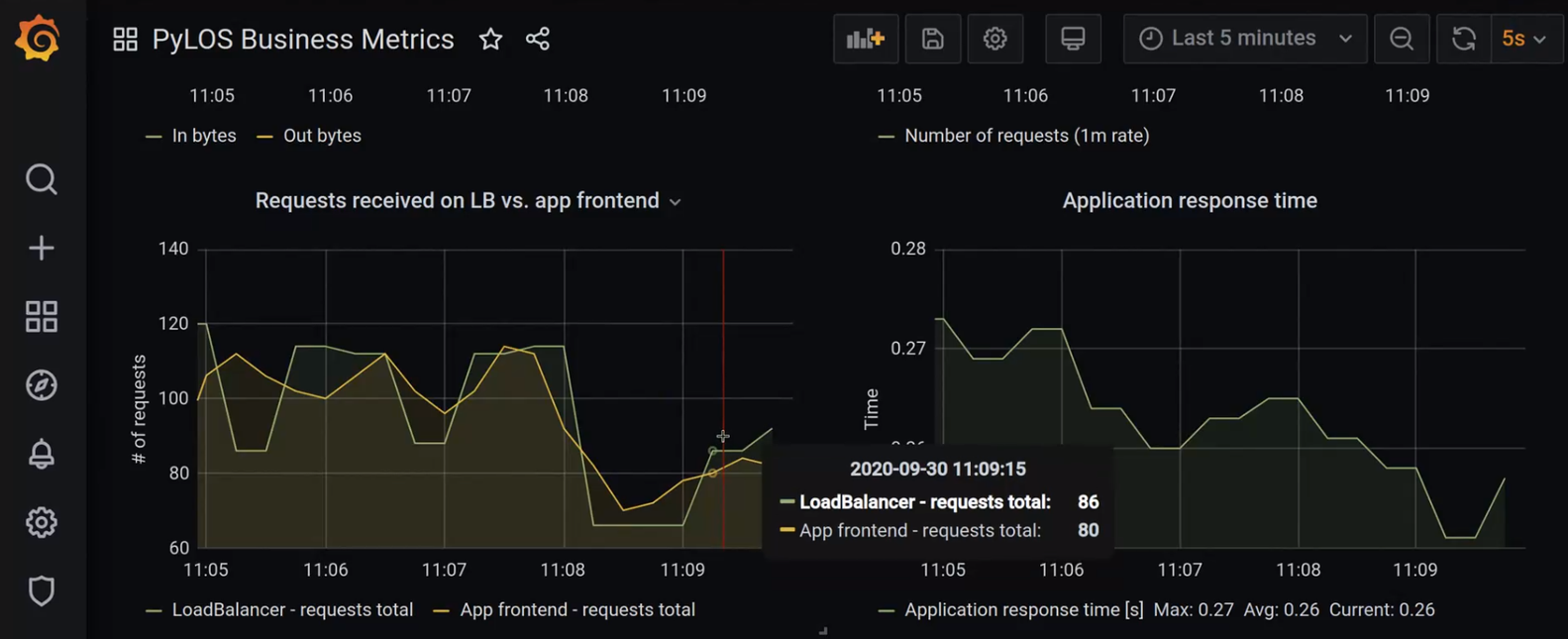
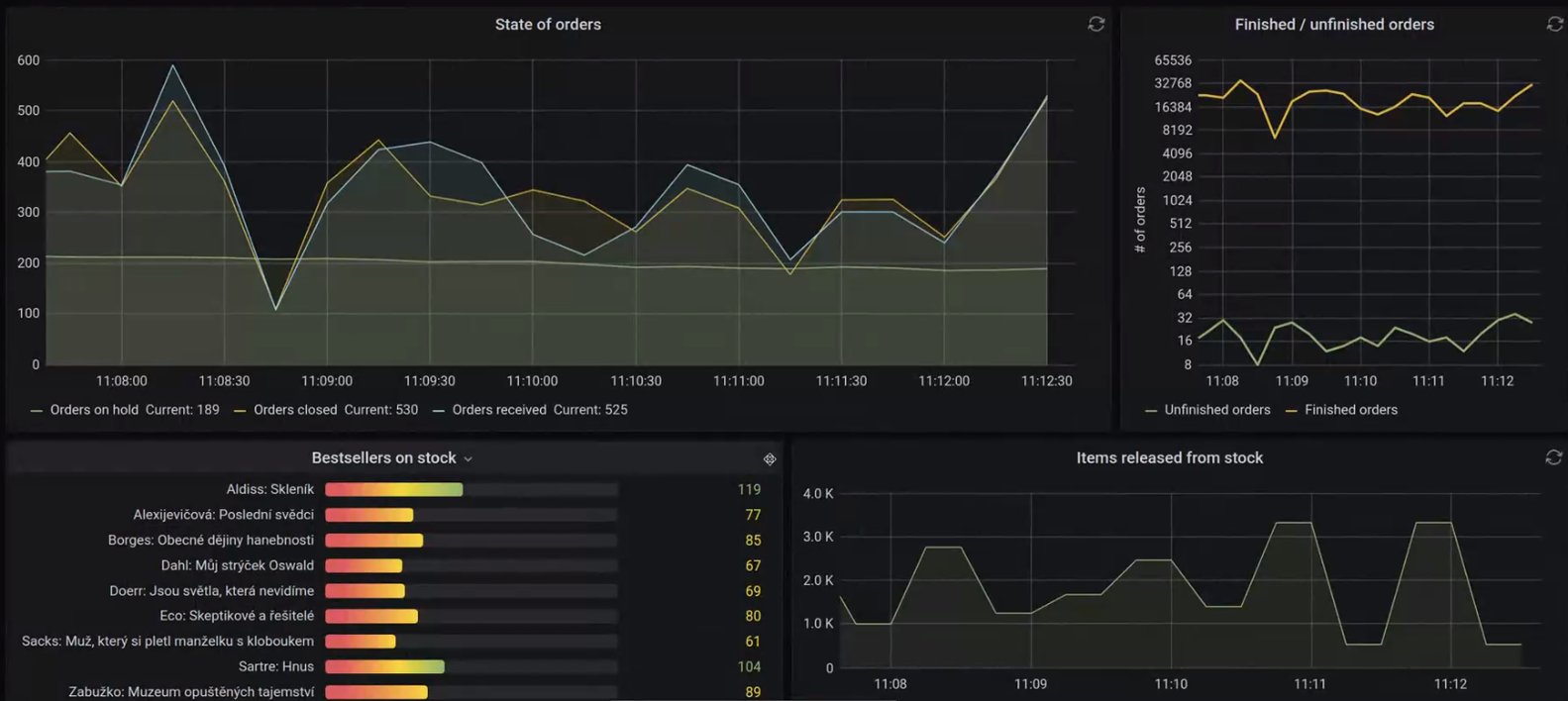
Nezapomínejme, že zpracovávat můžeme nejen data technických metrik. Vaše aplikace mohou publikovat také data business metrik. Např. stav zboží na skladě, objem příchozích objednávek apod. I pro business metriky lze navíc definovat alerty a při jejich aktivaci na ně zase automatizovaně reagovat. Na Red Hat Forum 2020 jsme nedávno prezentovali ukázku, kdy se při nedostatku zboží na skladě aktivoval alert, který skrze Alert Managera spustil serverless funkci nasazenou v AWS Lambda. Jakkoliv tohle není typický scénář využití Prometheus stacku, zajímavě ilustruje možnosti, které s sebou takto konstruované řešení pro zpracování metrik přináší.
Prometheus je technologie vhodná pro tradiční i cloudovou infrastrukturu, která dokáže agregovat data metrik ve statickém i dynamicky škálovaném prostředí - díky svému velmi dobře vystavěnému konceptu discovery. Definici agregovaných metrik pak nechává na samotných sledovaných systémech. Pro zavádění nových targetů a metrik tím pádem není zapotřebí konfigurační zásah ze strany monitoring týmu a definice těchto metrik se místo toho stává součástí životního cyklu samotných sledovaných systémů.



