
Slabý vítr, chorvatské svátky, devět námořníků a jedna motivační písnička složená s AI. Tohle je příběh o tom, jak se ELOS Sailing Team dostal na vrchol stupně vítězů.
7 min read
PUMPS Regata 2026: Vyhráli jsme. Neptun nás podržel!

Topics: ELOS Sailing Team Firemní kultura PUMPS Regata Chorvatsko Bavaria 46 Vítězství
14 min read
OpenShift v AWS: bezpečná instalace v Landing Zone
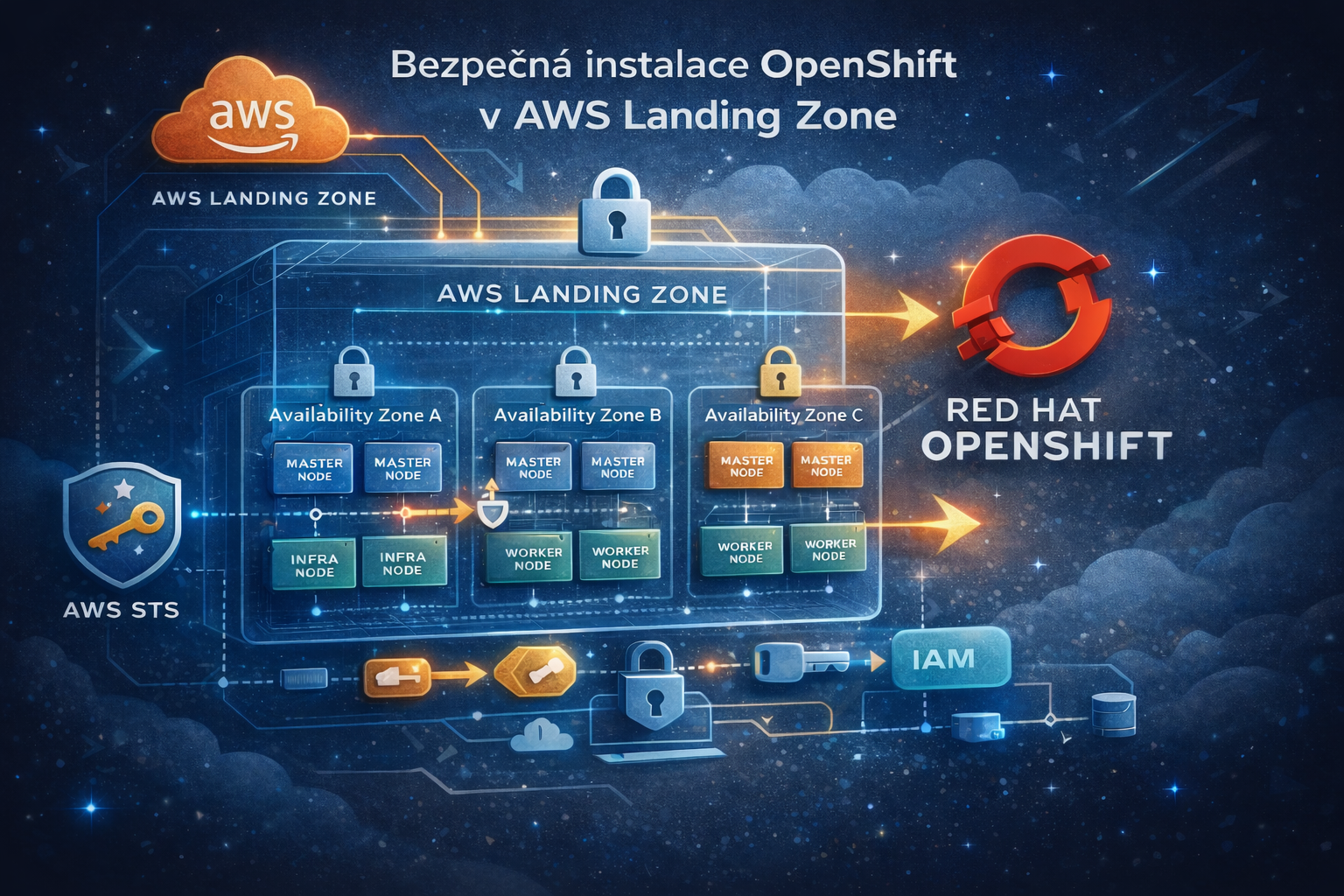
Instalace Red Hat OpenShift Container Platform (OCP) 4 do AWS účtu v rámci Landing Zone organizace přináší specifická omezení, která je třeba zohlednit již při plánování instalace. Landing Zone účty jsou typicky spravovány centrálně a bývají omezeny z hlediska IAM oprávnění, síťové topologie nebo bezpečnostních politik — například zákazem veřejných S3 bucketů, restrikcí na vytváření VPC či požadavkem na použití krátkodobých credentials místo dlouhodobých IAM klíčů.
Topics: DevOps Kubernetes Red Hat OpenShift Security AWS Landing Zone
3 min read
Red Hat certifikační program: co je nového a co zůstává stejné
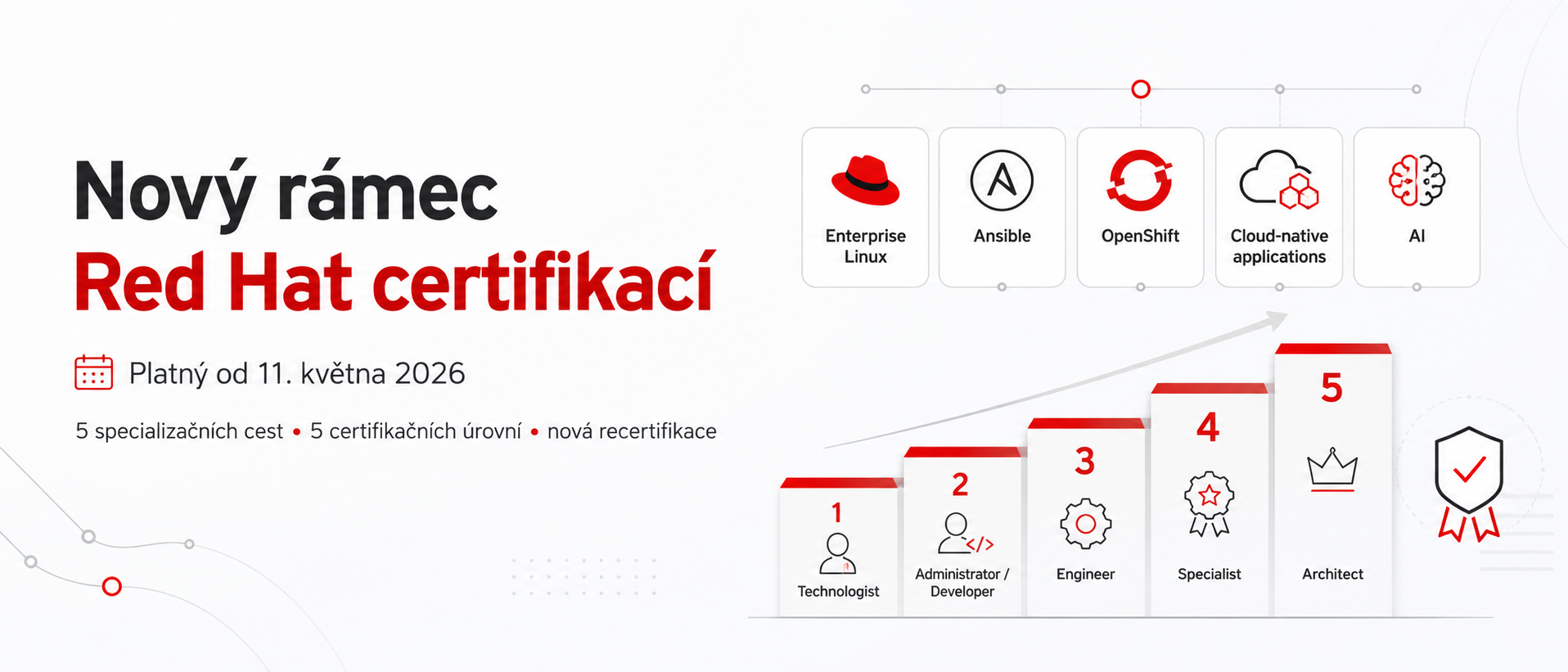
Od 11. května 2026 platí nový rámec Red Hat certifikací. Přináší přehlednější strukturu podle technologického zaměření a jasněji definované certifikační úrovně. Tady jsou klíčové změny.
Topics: Red Hat Training certifikace skills
5 min read
Nová generace aplikací v provozu: Čtyři věci, které byste měli vyřešit dříve, než vám přijdou do správy.

Aplikace se mění méně, než myslíte. Runtime kontrakt se mění víc, než čekáte.
Topics: finops DevOps Kubernetes
2 min read
Digitální suverenita v cloudu: proč se to týká každého IT týmu

Digitální suverenita. Ještě před dvěma lety to bylo téma pro vládní stratégy a právníky specializující se na GDPR. Dnes je to otázka, kterou dostáváme od IT manažerů, CTO i systémových administrátorů z finančního sektoru, energetiky i telekomunikací: Kdo skutečně kontroluje naši infrastrukturu? Co se stane, když se změní podmínky u našeho cloudového poskytovatele? Jak dokladujeme soulad s NIS2 nebo AI Actem?
Topics: Red Hat OpenShift
4 min read
ELOS Sailing Team: Suchá příprava, mokré sny a cesta za další trofejí

Zatímco servery jedou, my šlapeme do pedálů, visíme na žebřinách a modlíme se k Neptunovi.
4 min read
Co je Istio a proč je klíčové pro provoz microservices na Kubernetes
Moderní architektura založená na microservices přináší značnou provozní složitost. Jednotlivé služby jsou sice malé a nezávislé, ale ve větším systému jich mohou být desítky až stovky. Každá z nich musí řešit bezpečnost, vyvažování zátěže, monitoring a řízení provozu.
Zatímco u monolitické aplikace stačilo tyto oblasti řešit jednou, v microservices architektuře je nutné je řešit pro každou službu zvlášť. Kubernetes sice poskytuje základní podporu (např. objekt Service, L4 load balancing nebo service discovery), ale neřeší pokročilé scénáře, jako jsou:
- metriky na L7 úrovni,
- inteligentní směrování provozu,
- rate limiting,
- circuit breaking.
Samotný Kubernetes proto nestačí ke spolehlivému provozu většího počtu microservices. Jak systém roste, stává se jeho správa a observabilita stále obtížnější. Zde přichází ke slovu service mesh – dedikovaná infrastruktura, která řeší komunikaci mezi službami transparentně a centrálně, bez nutnosti zásahů do aplikačního kódu.
Topics: DevOps Kubernetes Service Mesh Red Hat OpenShift Microservices
3 min read
Red Hat Podman AI Lab: Bezpečné a efektivní experimentování s AI v kontejnerech

Vývoj AI aplikací se rychle posouvá z prototypů do reálného nasazení. Firmy hledají způsoby, jak bezpečně experimentovat s modely, integrovat je do svých DevOps procesů a zároveň udržet kontrolu nad daty i náklady. Právě zde vstupuje na scénu Podman AI Lab, novinka, která rozšiřuje funkce populárního container engine Podman o přehledné rozhraní pro práci s AI.
Podman AI Lab přináší možnost jednoduše vytvářet, spravovat a testovat AI řešení přímo lokálně – bez odesílání dat do cloudu a bez nutnosti složitých nástrojů. Pro DevOps týmy a architekty jde o výrazné zjednodušení celého procesu.
Topics: Red Hat OpenShift AI DevOps OpenSource Automation Podman AI Lab
8 min read
SELinux: Noční můra adminů nebo šance na lepší spánek?

Nedávno jsem byl na schůzce s klientem, kde popisovali svou linuxovou infrastrukturu a mimo jiné zmínili, že na RHEL operačních systémech mají vypnutý SELinux. Protože téma diskuze bylo jiné, tak jsem nepoložil základní otázku: „Proč?”
Topics: Red Hat Enterprise Linux SELinux Security Training
6 min read
OpenShift Local jako nástroj pro nasazení HashiCorp Vault v praxi
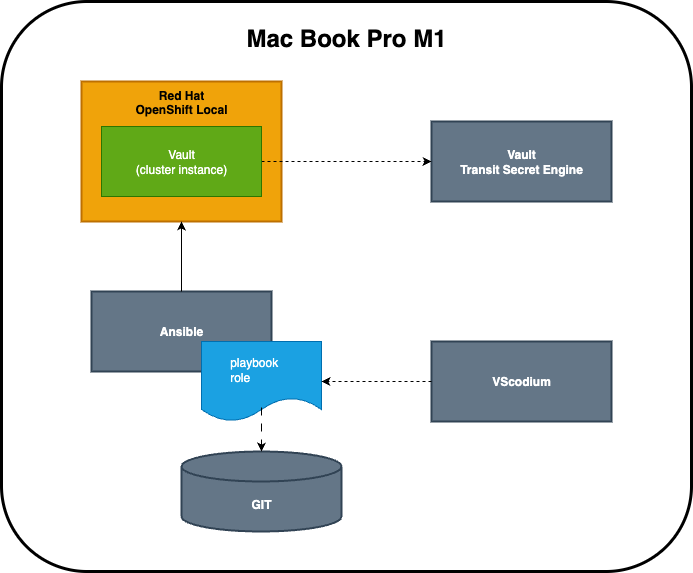
Pojďme se v článku seznámit s použitím Red Hat OpenShift Local na reálném use-case. Zároveň si odpovíme na otázku, zda jeho použití naplňuje prvky antického dramatu.
Topics: DevOps Kubernetes Ansible OpenShift Local Git Red Hat OpenShift
Chcete se dozvědět více?
Prostě jen klikněte na tlačítko níže a zarezervujte si s námi bezplatnou konzultaci.
